
A few people at the PETAA conference asked me about how I was making the fairytale images described here. In attempting to answer, I realised how much idiosyncratic image-generation knowledge I take for granted, so without going into too much detail, here's a little rundown.
Choosing an AI image model
There are a few image AI models to choose from. Right now the big four are Midjourney, DALLE, Stable Diffusion and Adobe Firefly.
I usually use Midjourney.
Midjourney is pretty much the best image system, for reasons I won't go into here, but at the moment you can only generate images in Discord, which is a chat-based community app popular among gamers, which can be a little confusing if you're not familiar with it.
DALLE has, by comparison, sucked—but the new DALLE3 is very, very good, and its integration into GPT4 creates a very interesting interactive experience.
You can access DALLE3 via Bing chat (for free) or via ChatGPT (if you pay for Pro).
Why is DALLE3 currently better than Midjourney?
DALLE3 is way better than the current Midjourney model at compositional coherence, especially when you have multiple elements in a scene.

Midjourney is often more beautiful and evocative, but if you ask for complex interaction between elements in the frame, MJ will often blend everything together in a weird soup. (FYI This might change in November/December.)
For example, for our recent Halloween/horror images, I wanted a picture of a deranged dad gobbling soil at the kitchen table. (An image based on a Goosebumps book.)
The challenge for any image model is that the combination of "eating" and "soil" is weird. Midjourney could get the soil on the table, but not in the character's mouth:

If I forced it to put the soil in the character's mouth, Midjourney couldn't help but change the soil to something like meat:

Whereas DALLE3 nailed the concept first go:

DALLE3 has better compositional coherence because it uses GPT4 as an intermediary language model:
- It has benefited from having GPT4 describe millions of training images (meaning DALLE3 has a relatively rich and nuanced "model" of the world).
- It also uses GPT4 to rewrite whatever image prompts you give it, because DALLE3 likes long, detailed prompts (unlike Midjourney, which prefers relatively vague, keyword-oriented prompts).
(So when you write a DALLE3 image prompt inside the ChatGPT app, GPT4 will write four variations of your prompt in quite elaborate detail in order to elicit a better output from DALLE3. Some people find this AI rewriting invasive, but I've found it to be pretty helpful, and you can always override it and insist that DALLE use specific wording.)
How to direct DALLE3 in ChatGPT
I don't use Bing. The only advice I can offer is how to use DALLE3 in ChatGPT:
- Talk to ChatGPT like you're an art director (so give it your brief, let it generate images, then refine with feedback)
- Learn to think like a language & image model (this will help you give better feedback)
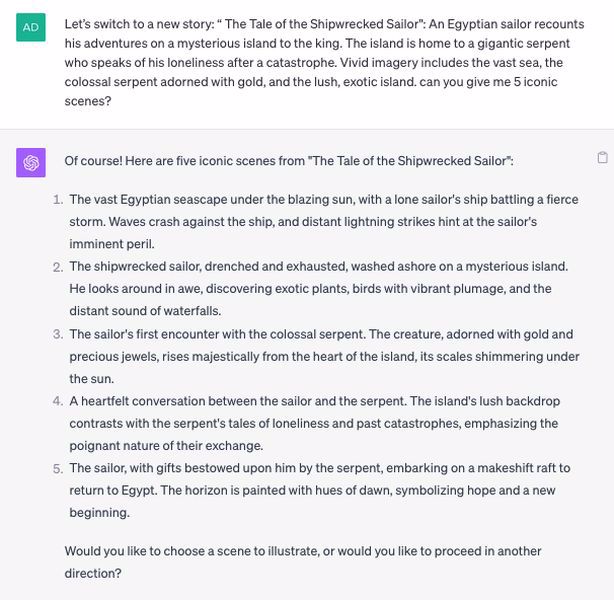
My basic system for these fairytale images was to give ChatGPT a tale and ask it to list 5-10 iconic moments:
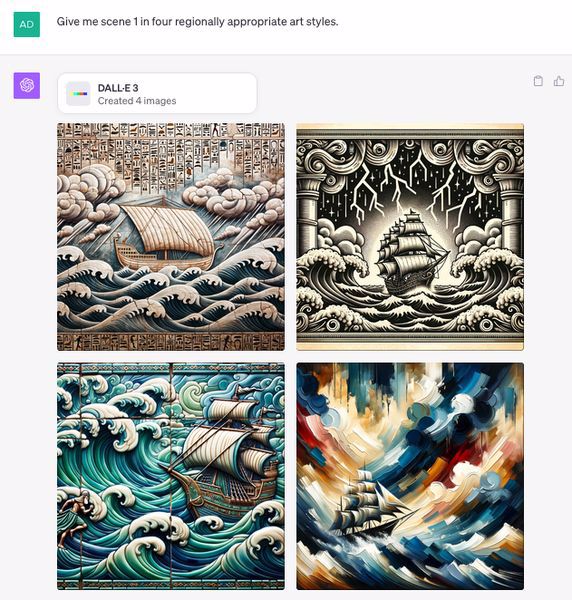
I'd ask it to render the first moment in a variety of art styles (sometimes including regionally or historically relevant styles):
I'd tell it which styles I preferred or keep iterating to find styles I liked. (DALLE3 will generate up to 4 images based on a single prompt at a time, so you can tell it to vary each prompt in 4 styles if you like.)

Each time it gives you a generation, you can either direct it to make changes or tell it to move to the next moment. (I also told ChatGPT that if I wanted it to move on I would simply enter "N" for next, that way I could happily watch the conference session and occasionally hit "N" to render a new set of images.)
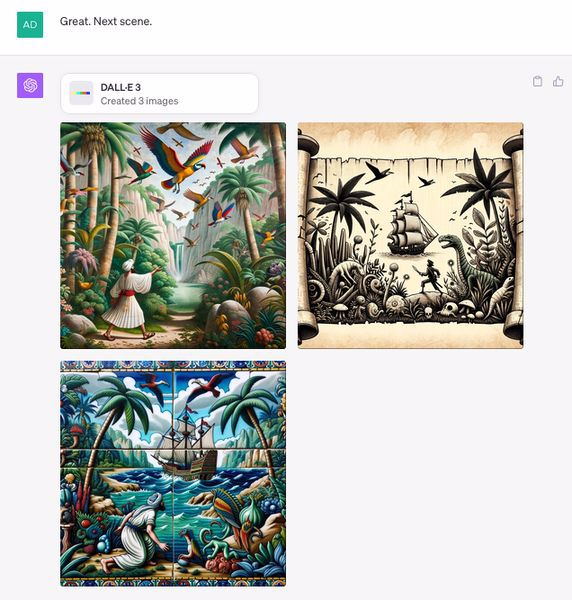
Finessing individual images
You can ask ChatGPT to make changes and it will do a pretty good job of figuring out what you want.

However, sometimes the system does get stuck in awkward patterns, which is where it helps to be able to think like an image model.
By that I mean, intuiting the prompt as a bundle of relationships, and developing a knack for spotting words and phrases that might send the model astray.
For example, ChatGPT suggested a Red Riding Hood image where the wolf is looking in the mirror, dressed in Granny's clothes. Great idea! But the DALLE renders kept showing the wolf's reflection, but no wolf standing in front of the mirror:
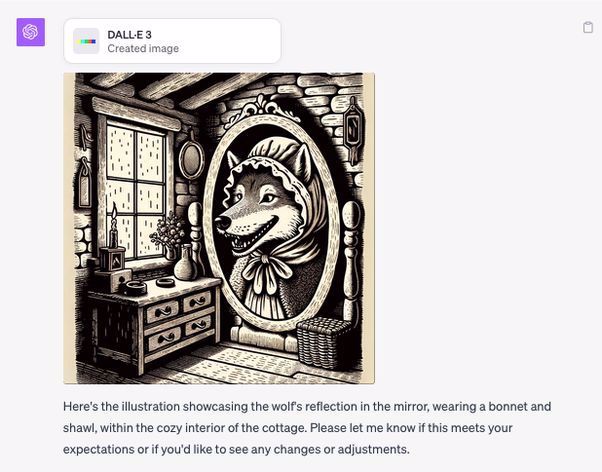
I knew from the spooky funhouse images we did for the Halloween image collections that DALLE3 has a very good understanding of subject and reflections, so that wasn't the problem.
So I looked at the prompt ChatGPT had written for DALLE and noticed that ChatGPT had used the line, "The surrounding room elements hint at the cozy interior of the cottage, with rustic furniture and warm lighting."
With my language & image model hat on, I could see how that line compels DALLE to include rustic furniture, which requires a wide shot—but when it's widening the shot it's focused on showing the furniture, not the wolf, which is how we wind up with an empty cabin with rustic furniture and a mirror with a wolf's reflection inside it.
I figured if that was the problem, then the solution was to use those environmental details to narrow DALLE's perspective instead of expanding it, so I told ChatGPT to use a different line: "The mirror frame and a few rustic items such as candle, hairbrush and dentures hint at the cozy interior of the grandmother's cottage, while warm lighting casts gentle shadows."
That is enough to Jedi mind-trick DALLE into focusing on the dresser and mirror, which brings the POV close enough that we can see the wolf's reflection but don't need to see the wolf himself:
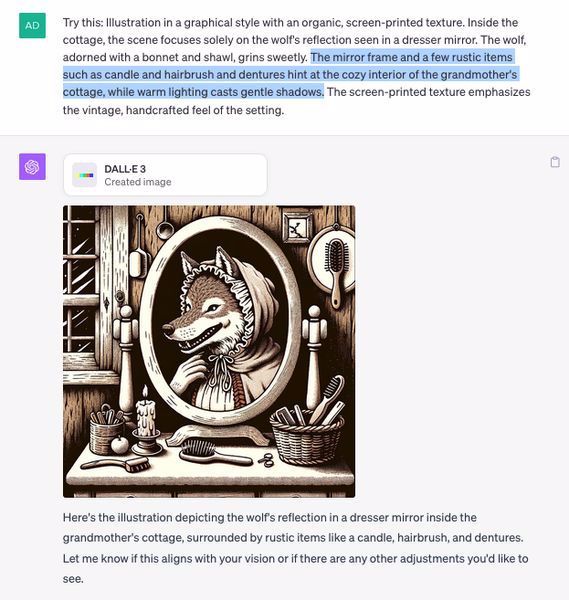
Of course, why grandma has brushes stuck to every surface of her house is a mystery—the AI models are eager to please!
I hope that's helpful
As I said, there's a lot of idiosyncratic knowledge I now take for granted, and those notes are just scratching the surface.
If you're interested in image generation I'd encourage you to pay for a subscription to DALLE3 or Midjourney and experiment, even if only to learn the capabilities of these machines.
If you have questions, feel free to ask me.